EdgeTA: Retraining Multiple Foundation Models
for Evolving Data at Edge
Table of Contents
- 1. Introduction
- 2. Code and Installation
- 3. Running Example 1: Supporting a Hugging Face FM Vision Transformer
- 4. Running Example 2: Supporting a Hugging Face FM CLIP
- 5. Running Example 3: Supporting a user-specified FM SAM
- 6. Running Example 4: Supporting a user-specified FM GLIP
- 7. Running Example 5: Supporting a Hugging Face FM GPT-Neo
- 8. Running Example 6: Supporting a Hugging Face FM Roberta
- 9. Implementation (Development API Documentation)
- 10. Experimental evaluation in TMC 2024 submission
1. Introduction
Foundation models (FMs) such as large language models are the driving force of the next generation artificial intelligence systems. The trend of deploying FMs at edge challenges their scaling potential when encountering massive new input data with compressed model sizes and constrained device resources. The prior art sheds light on learning new tasks and domains (data feature shifts) based on deployed networks. However, such learning approaches exacerbate the existing limitations: (i) predetermined network architectures lower model accuracy, and (ii) fixed model sizes hinder resource allocation optimization at a finer granularity.
In this paper, we propose EdgeTA, a lightweight, neuron-grained scaling solution to unlock FMs' scaling potency in edge intelligence systems. EdgeTA achieves high accuracy and low overheads in model retraining by adaptively transforming a FM into a compact model that retains the most important neurons to the current input data. At run-time, EdgeTA determines optimal model sizes and assigned resources for multiple applications to maximize their overall accuracy. We implement EdgeTA in prevalent FMs of natural language processing, computer vision and multimodal applications and compare it against state-of-the-art techniques. Evaluation results show that our approach improves accuracy by 21.88% while reducing memory footprint and energy consumptions by 27.14% and 65.65%, and further achieves 15.96% overall accuracy improvement via neuron-grained resource scheduling.
2. Code and Installation
The code is released in https://huggingface.co/spaces/LINC-BIT/EdgeTA/tree/main. You can use the "git clone" command to clone this repository:
git clone https://huggingface.co/spaces/LINC-BIT/EdgeTA
The directory structure is organized as below:
- data: it contains datasets implementation
- dnns: it contains models implementation
- experiments: it contains the files to launch the experiments in the submitted paper
- methods: it contains EdgeTA implementation
- new_impl: it applies EdgeTA in several SOTA FMs: CLIP, SAM, and GLIP
- utils: it contains several our implemented tool packages
2.1 Requirements
- Linux and Windows
- Python 3.8+
- CUDA 10.2+
2.2 Preparing Environment
First, create a conda virtual environment and activate it:
conda create -n EdgeTA python=3.8
conda activate EdgeTA
Second, install torch and torchvision according to the offical site.

Get the installation command according to the selection in the official site, and copy them to the terminal.
Finally, install the required dependencies via pip:
pip install -r requirements.txt
3. Running Example 1: Supporting a Hugging Face FM Vision Transformer
3.1 Settings
Models. We use a semantic segmentation model based on Vision Transformer from Hugging Face as an example to explain how to connect a Hugging Face FM to the EdgeTA.
Datasets. We use datasets GTA5 and SuperviselyPerson as the source domain, and datasets Cityscapes and BaiduPerson as the target domain.
3.2 Offline Elastic Proxy Construction
Run the following command sequentially to pre-train the knowledge base and index:
python experiments/elasticdnn/vit_b_16/offline/fm_lora/cls/cls.py
python experiments/elasticdnn/vit_b_16/offline/fm_to_md/cls_md_wo_fbs.py
python experiments/elasticdnn/vit_b_16/offline/fm_to_md/cls_md_index.py
Note that the file path of the model checkpoint in last two files should be modified manually.
Run the following command to open TensorBoard and watch the metrics (e.g. losses and accuracy) during the training process:
tensorboard --logdir <the file path of tensorboard logs outputed in the terminal>
Here are three TensorBoard screenshots when three commands above are running:
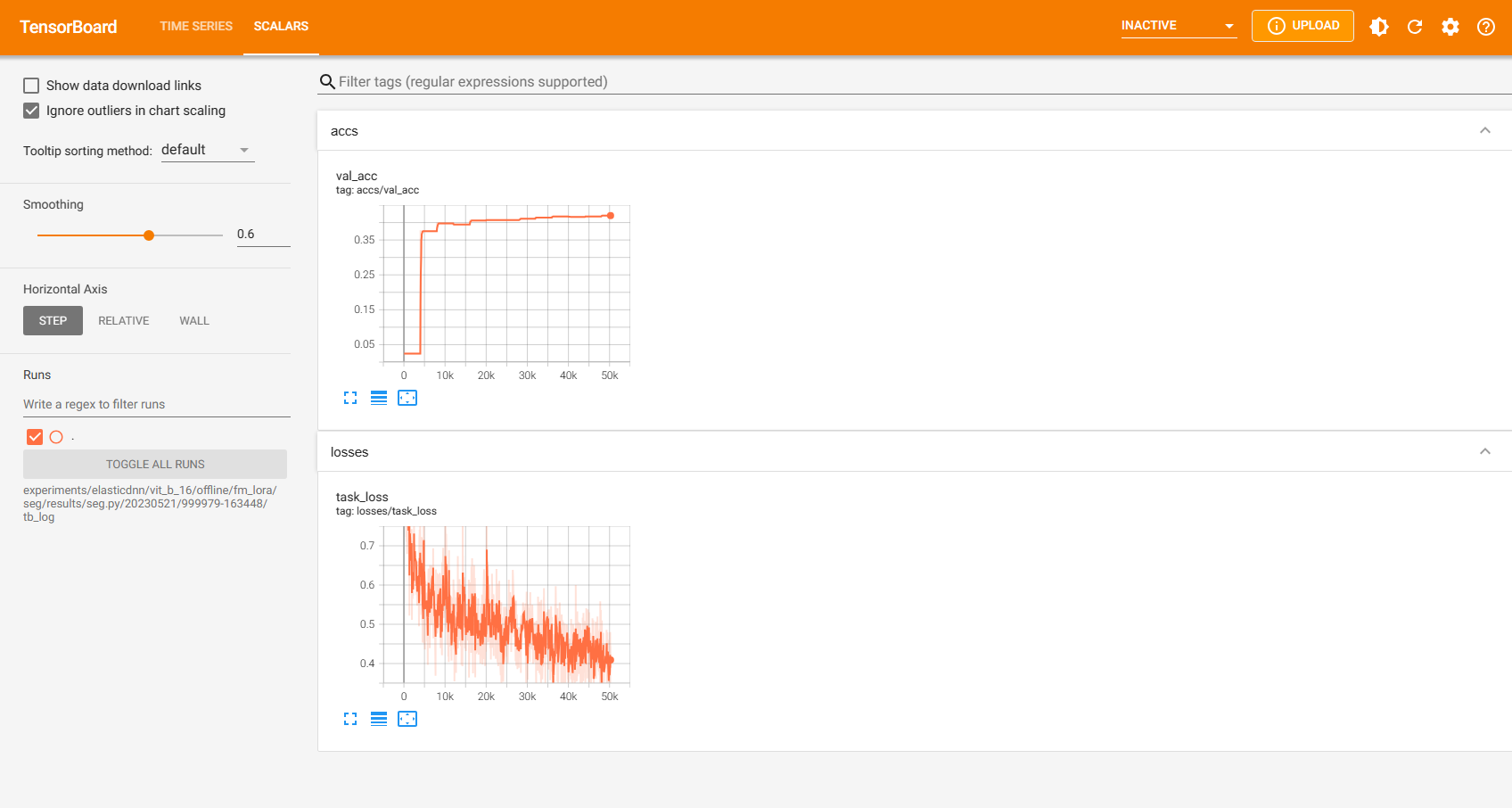
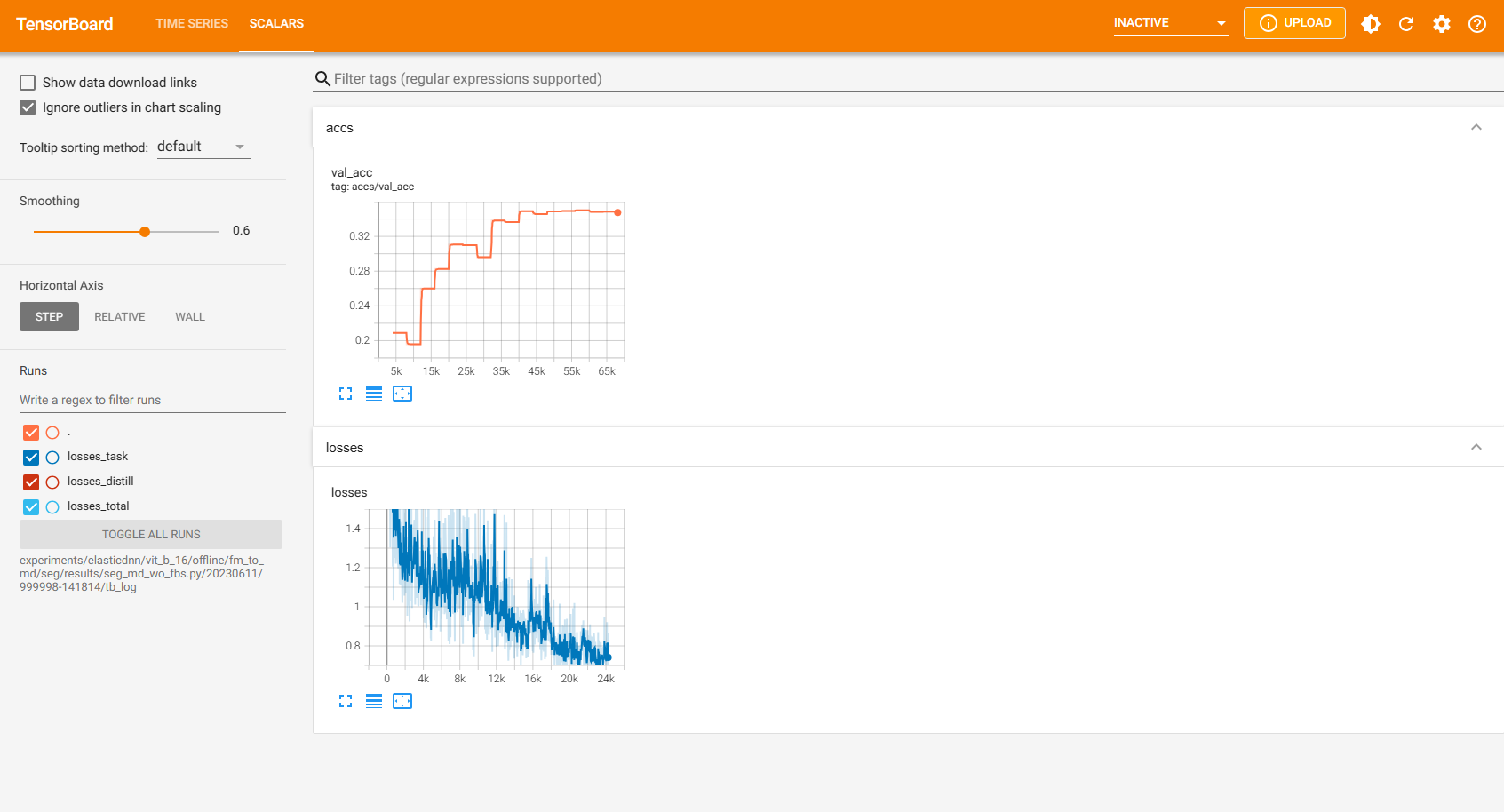
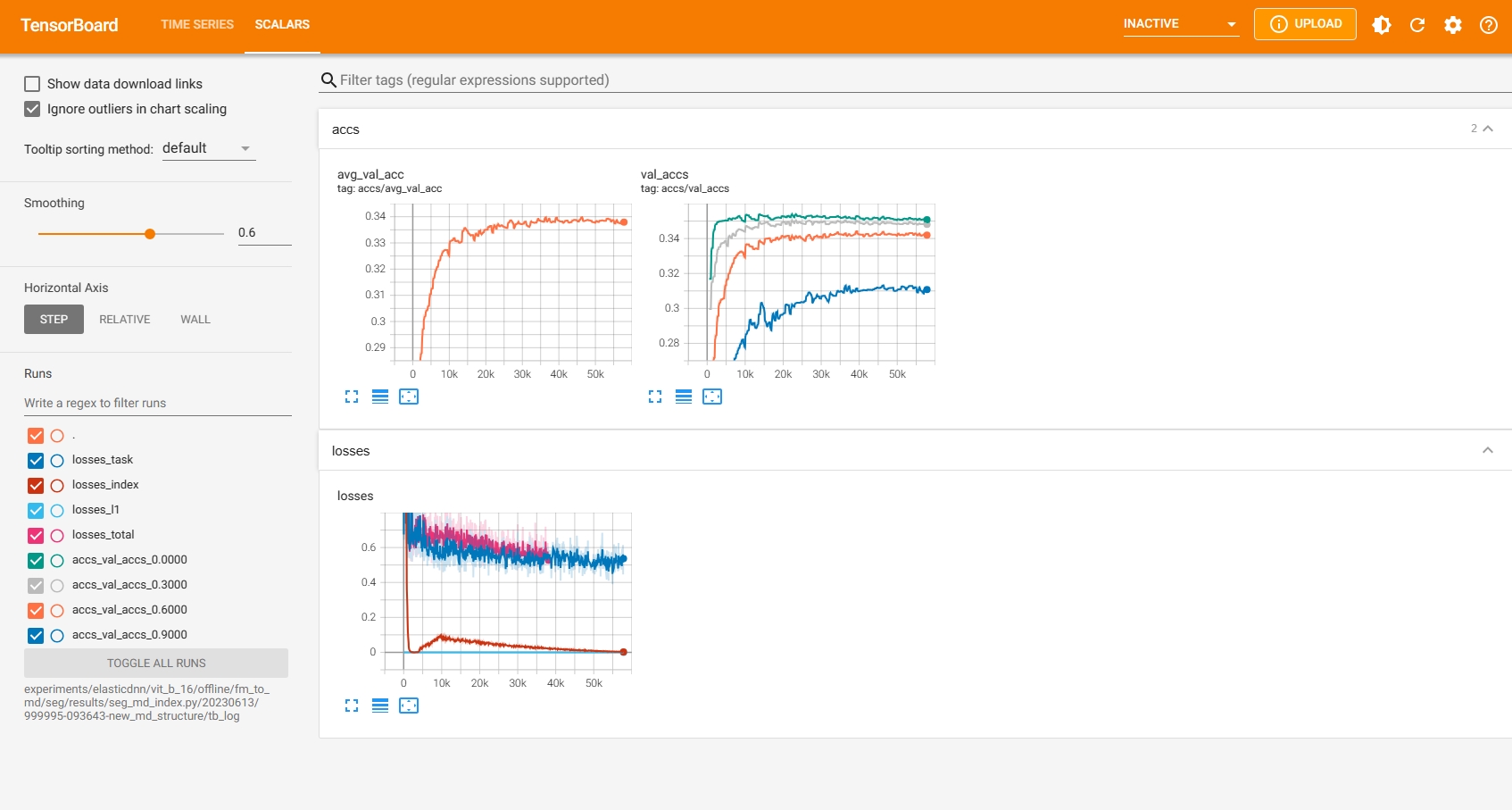
3.3 Online Evolving Input Data Adaptation
Run the following command to evaluate EdgeTA over evolving data:
python experiments/elasticdnn/vit_b_16/online_new/cls/cls.py
You can also launch TensorBoard to watch the retraining accuracy and time during the retraining process. Here is a screenshot:
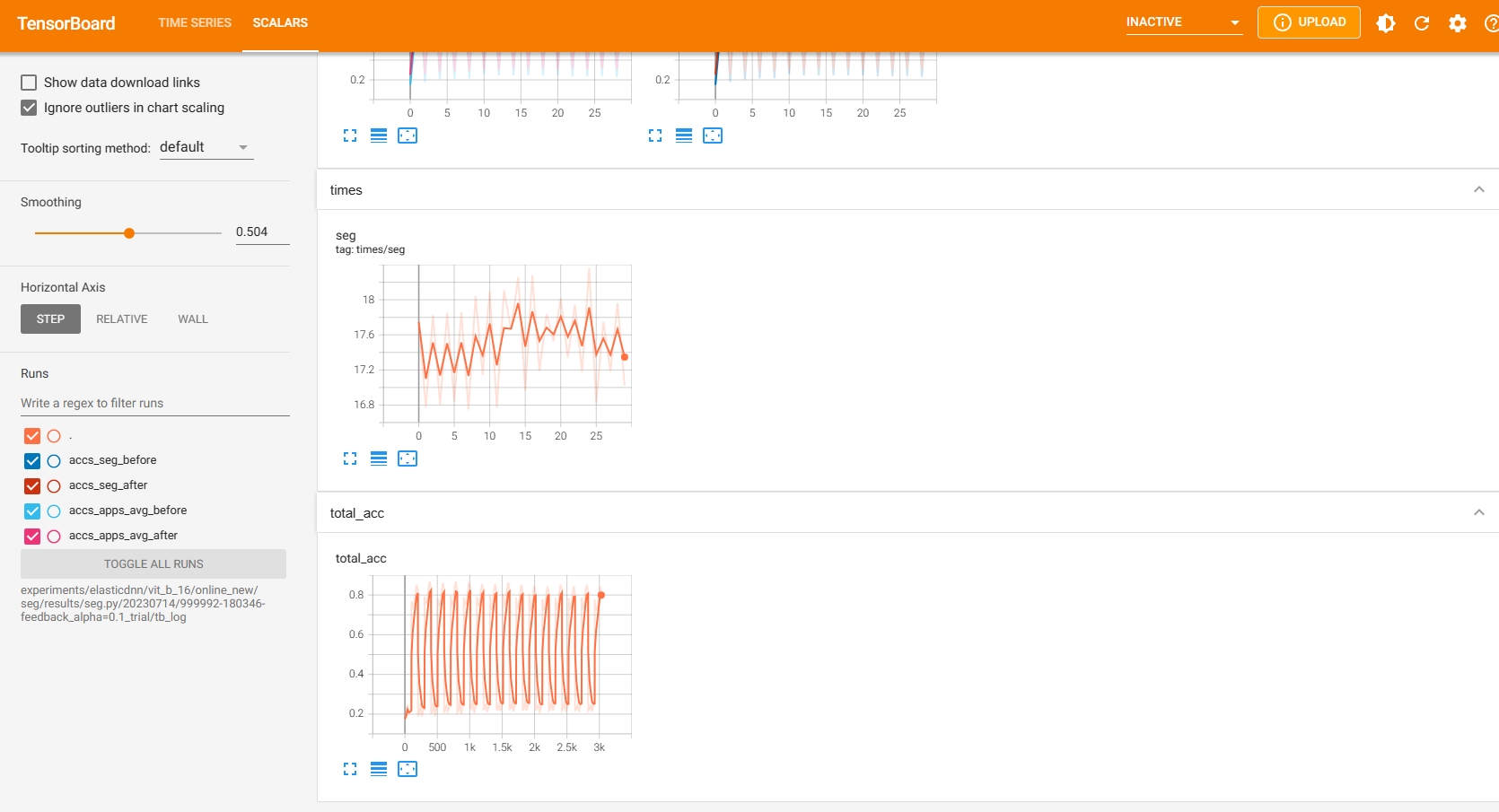
(Optional) 3.4 Tuning the hyperparameters
Most of hyperparameters are common and easy to understand (e.g. batch size, learning rate, and optimizer arguments, etc). We introduce some unique hyperparameters in EdgeTA below.
For python experiments/elasticdnn/vit_b_16/offline/fm_lora/cls/cls.py:
- ab_r: the value of r in LoRA.
For python experiments/elasticdnn/vit_b_16/offline/fm_to_md/cls_md_wo_fbs.py:
- sample_size: the size of an input sample. For typical image workloads, the size is (1, 3, 224, 224). For language workloads, you can directly pass in a tokenized sample directory instead of a size.
- generate_md_width_ratio: the ratio of the original FM's width to knowledge base's width. We recommend it is 4 or 8, which means that the knowledge base has 1/4 or 1/8 model size of the original FM.
- distill_loss_weight: it controls the strength of distilling the original FM's feature to the knowledge base's feature using feature-based knowledge distillation. This helps improve the accuracy of the knowledge base.
For python experiments/elasticdnn/vit_b_16/offline/fm_to_md/cls_md_index.py:
- FBS_r: the value of r in FBS module. We recommend it is 16.
- indexes_optimizer_args: the arguments of the optimizer used in training the neuron index between the knowledge base and the FM.
- min_sparisty and max_sparsity: in each training iteration, the knowledge base is set to a random sparsity and then trained (refer to dynamic neural networks). min_sparisty and max_sparsity determine that the maximal model size and the minimal model size of the generated proxy model. For example, if min_sparisty = 0 and max_sparsity = 0.9, the maximal model size of the proxy model is the same to the knowledge base, and the minimal model size of the proxy model is 10% of the knowledge base.
- bn_cal_num_iters: BN statstics is unstable during the training of dynamic neural networks (refer to S-Net (ICLR'19)). Therefore, before testing the accuracy of the knowledge base, its BN statstics should be calibrated using several iterations of inference on the test dataset (if the model has any BN layers).
- index_init: how the value of neuron index is initialized. We recommend it is 'zero'.
4. Running Example 2: Supporting a Hugging Face FM CLIP
4.1 Settings
Models. We use a image classification model based on CLIP from Hugging Face as an example to explain how to connect a Hugging Face FM to the EdgeTA.
Datasets. We use datasets GTA5 and SuperviselyPerson as the source domain, and datasets Cityscapes and BaiduPerson as the target domain. We convert these semantic segmentation datasets into image classification datasets by cropping and saving the images in the segmentation bounding boxes.
4.2 Offline Elastic Proxy Construction
Run the following command sequentially to pre-train the knowledge base and index:
python new_impl/cv/clip/cls.py
python new_impl/cv/clip/cls_md_wo_fbs.py
python new_impl/cv/clip/cls_md_index.py
Note that the file path of the model checkpoint in last two files should be modified manually.
Run the following command to open TensorBoard and watch the metrics (e.g. losses and accuracy) during the training process:
tensorboard --logdir <the file path of tensorboard logs outputed in the terminal>
Here are three TensorBoard screenshots when three commands above are running:
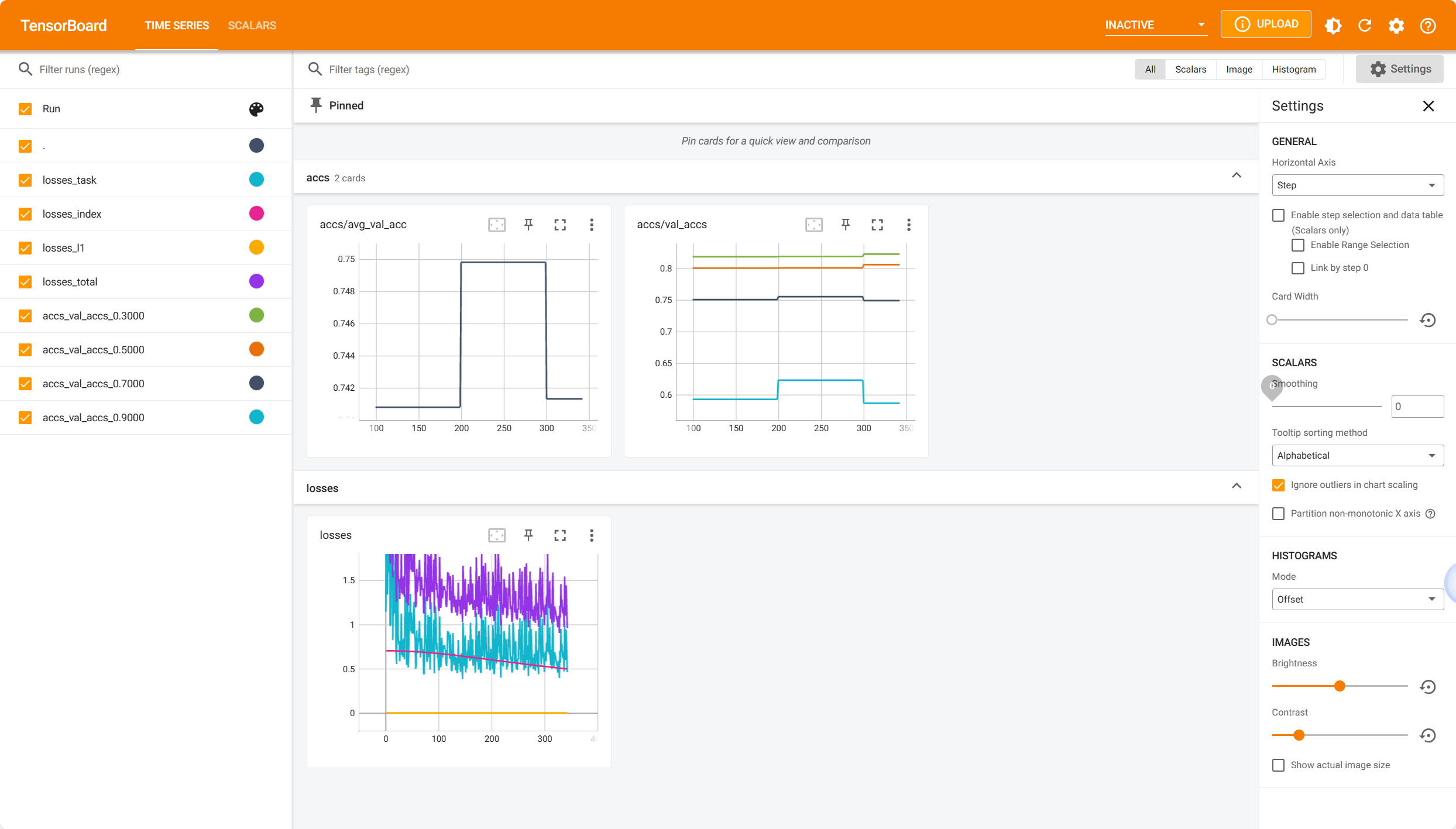
4.3 Online Evolving Input Data Adaptation
Run the following command to evaluate EdgeTA over evolving data:
python new_impl/cv/clip/cls_online.py
You can also launch TensorBoard to watch the retraining accuracy and time during the retraining process. Here is a screenshot:
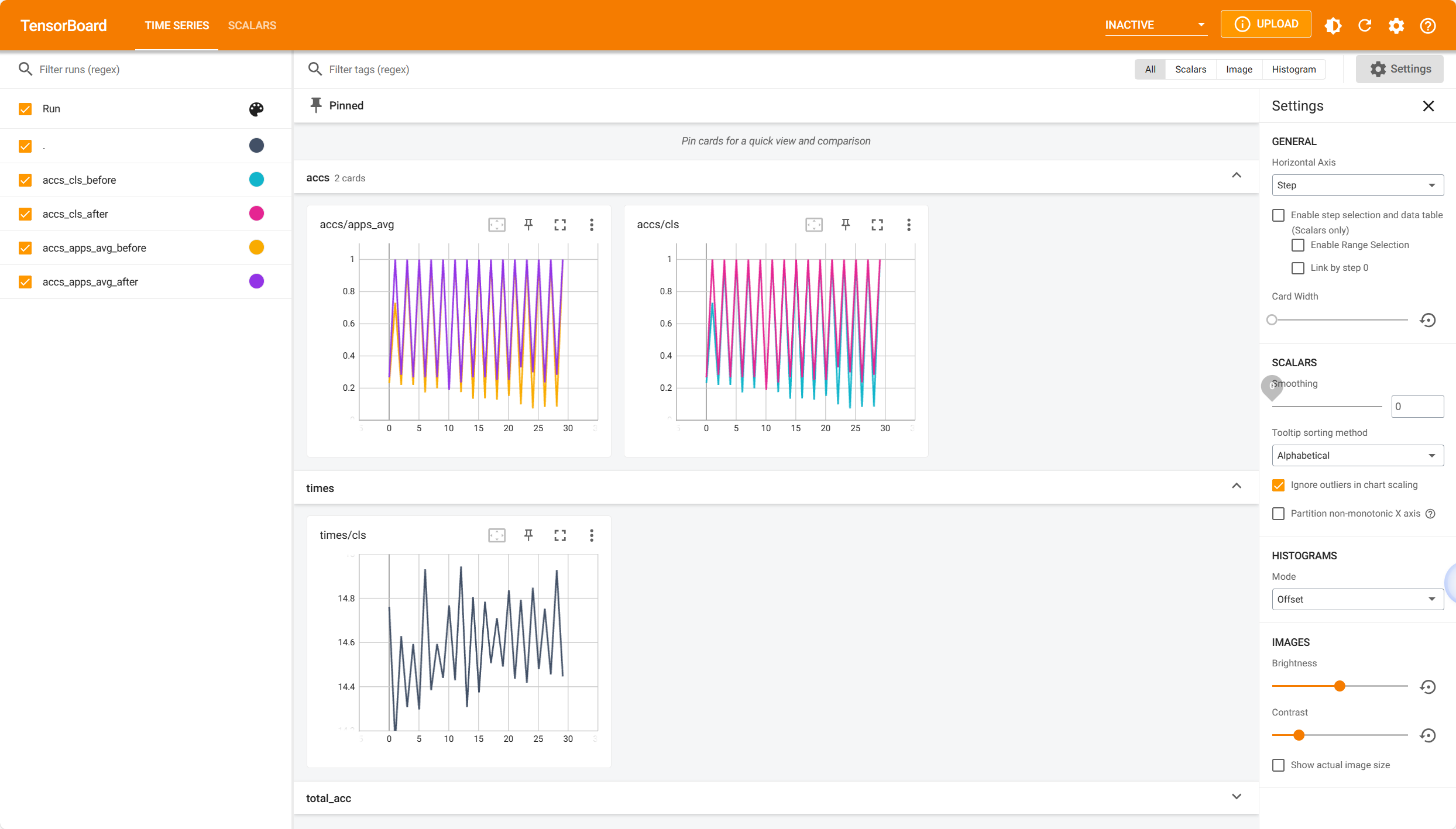
5. Running Example 3: Supporting a user-specified FM SAM (Segment Anything)
5.1 Settings
Models. We use the SOTA segmentation foundation model SAM. In this example, we support SAM using our designed standard FM API to explain how to connect a user-specified FM to the EdgeTA.
Datasets. We use datasets GTA5 and SuperviselyPerson as the source domain, and datasets Cityscapes and BaiduPerson as the target domain.
5.2 Offline Elastic Proxy Construction
Run the following command sequentially to pre-train the knowledge base and index:
python new_impl/cv/sam/seg.py
python new_impl/cv/sam/seg_md_wo_fbs.py
python new_impl/cv/sam/seg_md_index.py
Note that the file path of the model checkpoint in last two files should be modified manually.
Run the following command to open TensorBoard and watch the metrics (e.g. losses and accuracy) during the training process:
tensorboard --logdir <the file path of tensorboard logs outputed in the terminal>
Here are three TensorBoard screenshots when three commands above are running:
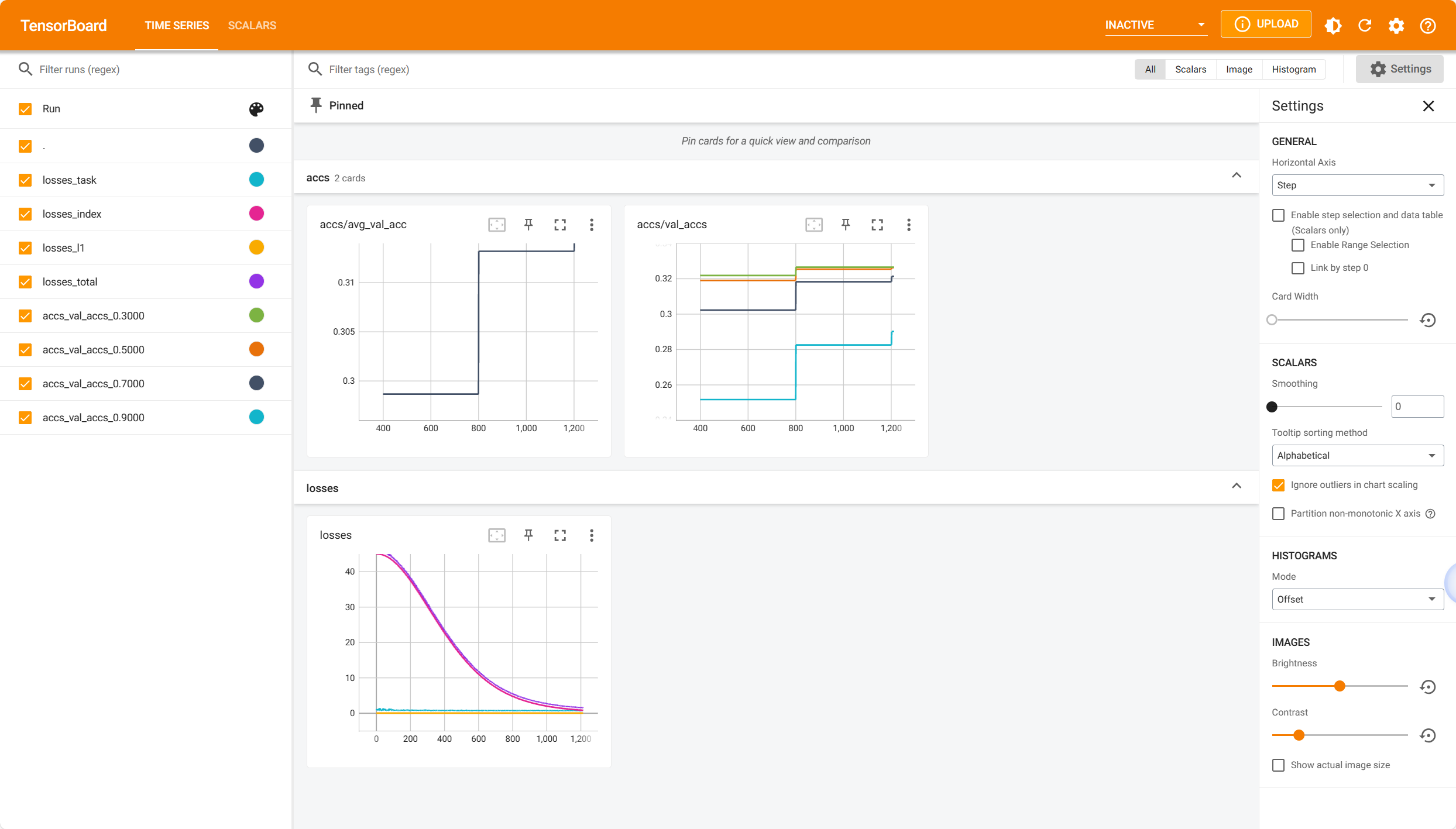
5.3 Online Evolving Input Data Adaptation
Run the following command to evaluate EdgeTA over evolving data:
python new_impl/cv/seg/seg_online.py
You can also launch TensorBoard to watch the retraining accuracy and time during the retraining process. Here is a screenshot:
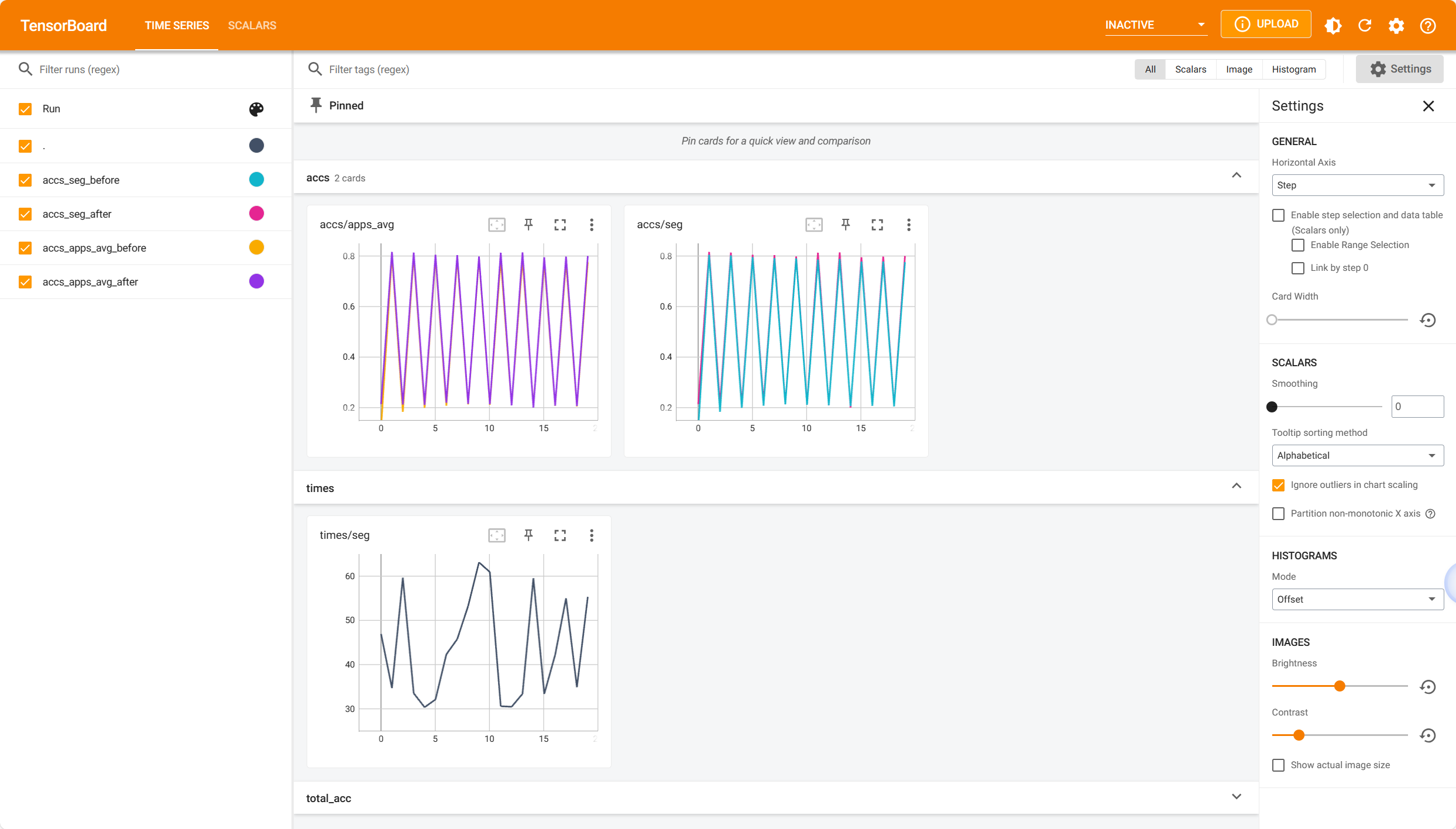
6. Running Example 4: Supporting a user-specified FM GLIP
6.1 Settings
Models. GLIP is a language image pretrained model used to learn object level, language aware, and semantically rich visual representations. GLIP combines object detection and phase grounding for pre training, enabling object detection of images based on prompts. In this example, we support GLIP using our designed standard FM API to explain how to connect a user-specified FM to the EdgeTA.
Because there is no GLIP model code in the transformers library, you need to download the code, the weight and the config of the GLIP model from github. Then you should place them under the path "new_impl/cv/glip/object_detection/pretrained_ model" and setup the code. In addition, you should also modify the code about GLIP to make the GLIP model (GeneralizedVLRCNN) outputs the token_logits and the dot_product_logits when it's in eval mode.
Datasets. In the example, we will use datasets COCO2017 as the source domain dataset, and Cityscapes and GTA5 as the target domain datasets.
6.2 Offline Elastic Proxy Construction
Run the following command sequentially to pre-train the knowledge base and index:
python new_impl/cv/glip/object_detection/det_lora.py
python new_impl/cv/glip/object_detection/det_md_wo_fbs.py
python new_impl/cv/glip/object_detection/det_md_w_fbs_index.py
Note that the file path of the model checkpoint in last two files should be modified manually.
Run the following command to open TensorBoard and watch the metrics (e.g. losses and accuracy) during the training process:
tensorboard --logdir <the file path of tensorboard logs outputed in the terminal>
Here are three TensorBoard screenshots when three commands above are running:
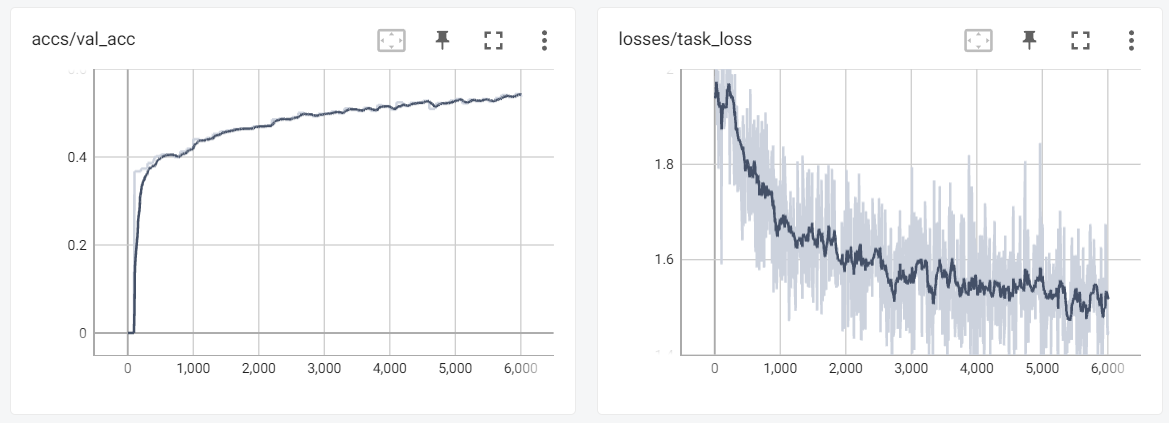
6.3 Online Evolving Input Data Adaptation
Run the following command to evaluate EdgeTA over evolving data:
python new_impl/cv/glip/object_detection/det_online.py
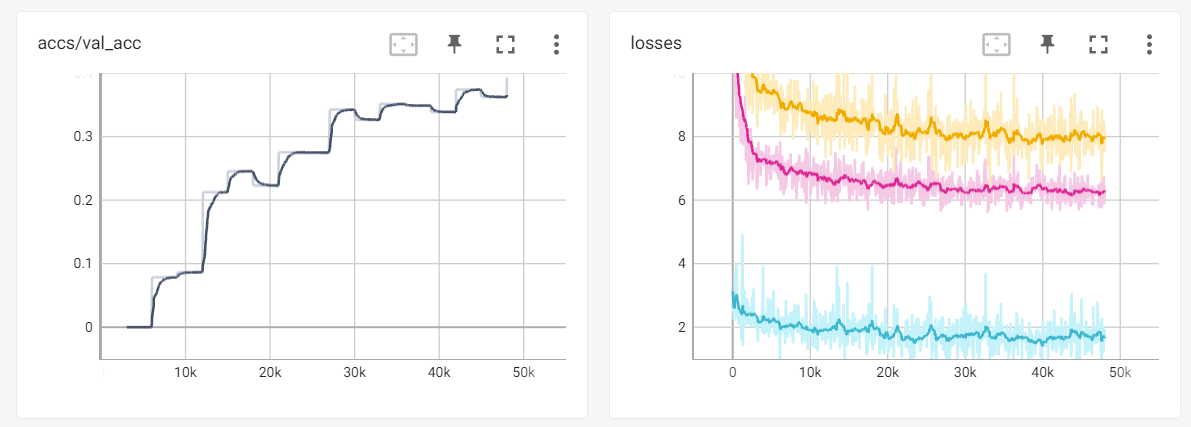
You can launch TensorBoard to watch the retraining mAP@50 score and time during the retraining process. Here is a screenshot:
7. Running Example 5: Supporting GPT-Neo
7.1 Settings
Models
GPT-Neo is an open-source text AI model launched by German company Eleuther Artificial Intelligence in late March 2021 to compensate for the lack of open-source GPT-3 models. In this example, we support GPT-Neo using our designed standard FM API to explain how to connect a user-specified FM to the EdgeTA.
Datasets
In the example, we will use datasets No_robots as the source domain dataset. Medicine-tasks and law-tasks as the target domain datasets. They are all conversational datasets.
7.2 Offline Elastic Proxy Construction
Run the following command sequentially to pre-train the knowledge base and index:
python new_impl/nlp/gpt-neo/text_generation/gen_lora.py
python new_impl/nlp/gpt-neo/text_generation/gen_md_wo_fbs.py
python new_impl/nlp/gpt-neo/text_generation/gen_md_w_fbs_index.py
Note that the file path of the model checkpoint in last two files should be modified manually.
Run the following command to open TensorBoard and watch the metrics (e.g. losses and accuracy) during the training process:
tensorboard --logdir <the file path of tensorboard logs outputed in the terminal>
Here are three TensorBoard screenshots when three commands above are running:
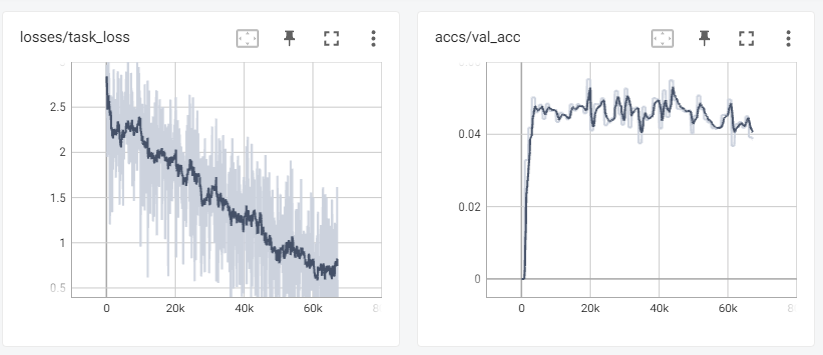
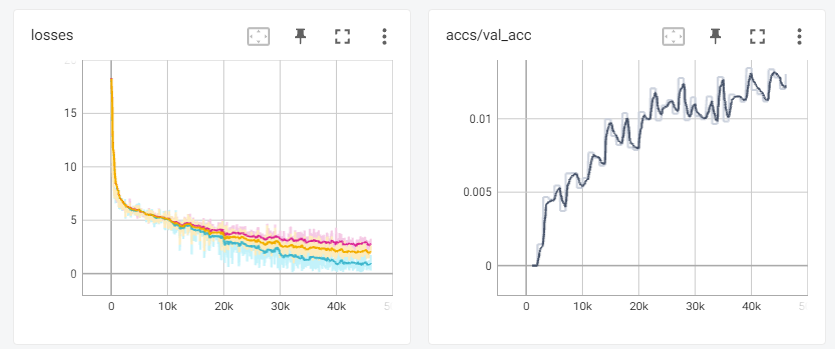
7.3 Online Evolving Input Data Adaptation
Run the following command to evaluate EdgeTA over evolving data:
python new_impl/nlp/gpt-neo/text_generation/gen_online.py
You can launch TensorBoard to watch the retraining mAP50 score and time during the retraining process. Here is a screenshot:
8. Running Example 6: Supporting Roberta
8.1 Settings
Models
We used the base version of the Roberta model (an improved version of Bert) to demonstrate how to connect a Hugging Face FM to the EdgeTA.
Datasets
We use the dataset named HL5Domains which includes five datasets called ApexAD2600Progressive, CanonG3, CreativeLabsNomadJukeboxZenXtra40GB, NikonCoolpix4300 and Nokia6610. Among them, ApexAD2600Progressive, CanonG3 and CreativeLabsNomadJukeboxZenXtra40GB are used as the source domains, and the datasets NikonCoolpix4300 and Nokia6610 are used as the target domains. They are all from amazon.com.
8.2 Offline Elastic Proxy Construction
Run the following command sequentially to pre-train the knowledge base and index:
python new_impl/nlp/roberta/sentiment-classification/cls_lora.py
python new_impl/nlp/roberta/sentiment-classification/cls_md_wo_fbs.py
python new_impl/nlp/roberta/sentiment-classification/cls_md_w_fbs_index.py
Note that the file path of the model checkpoint in last two files should be modified manually.
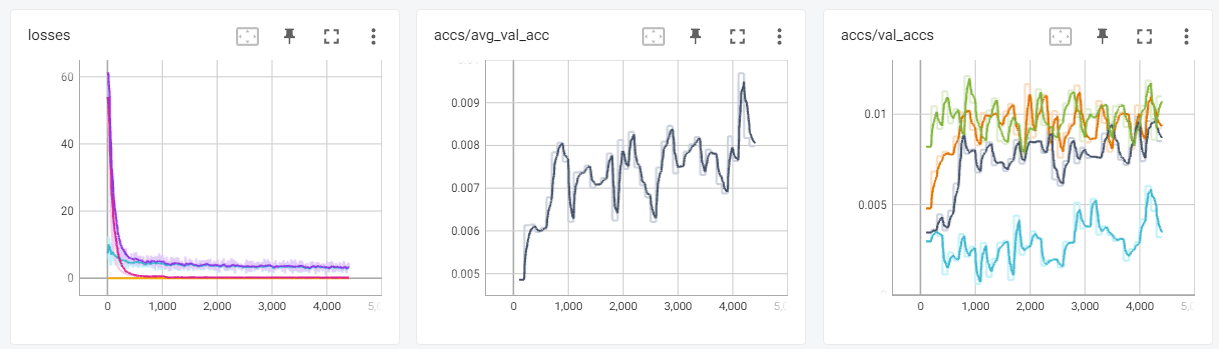
Run the following command to open TensorBoard and watch the metrics (e.g. losses and accuracy) during the training process:
tensorboard --logdir <the file path of tensorboard logs outputed in the terminal>
Here are three TensorBoard screenshots when three commands above are running:
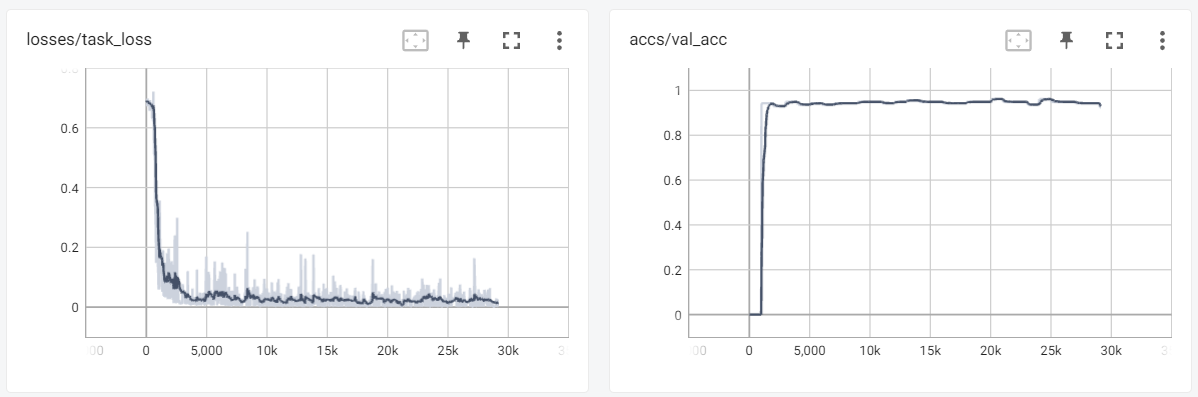
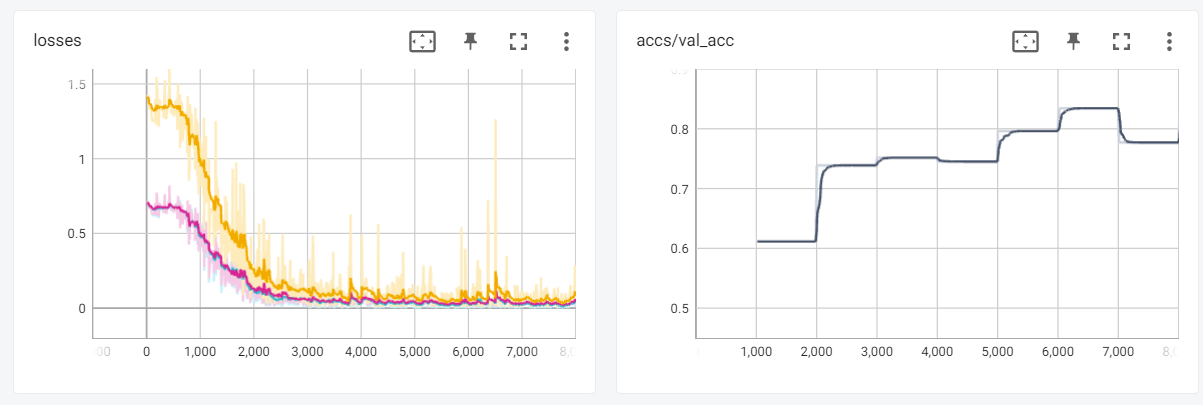
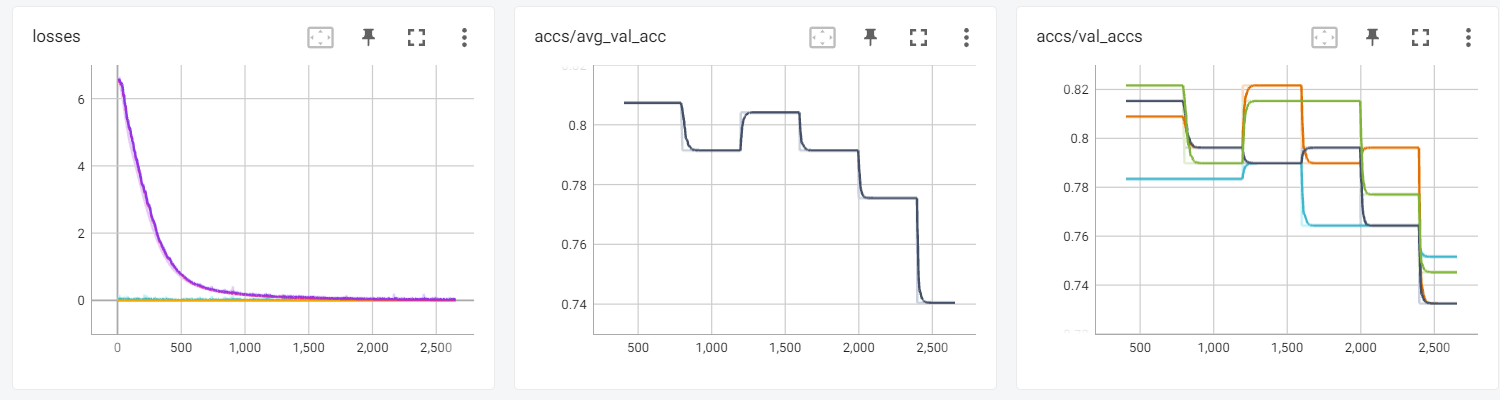
8.3 Online Evolving Input Data Adaptation
Run the following command to evaluate EdgeTA over evolving data:
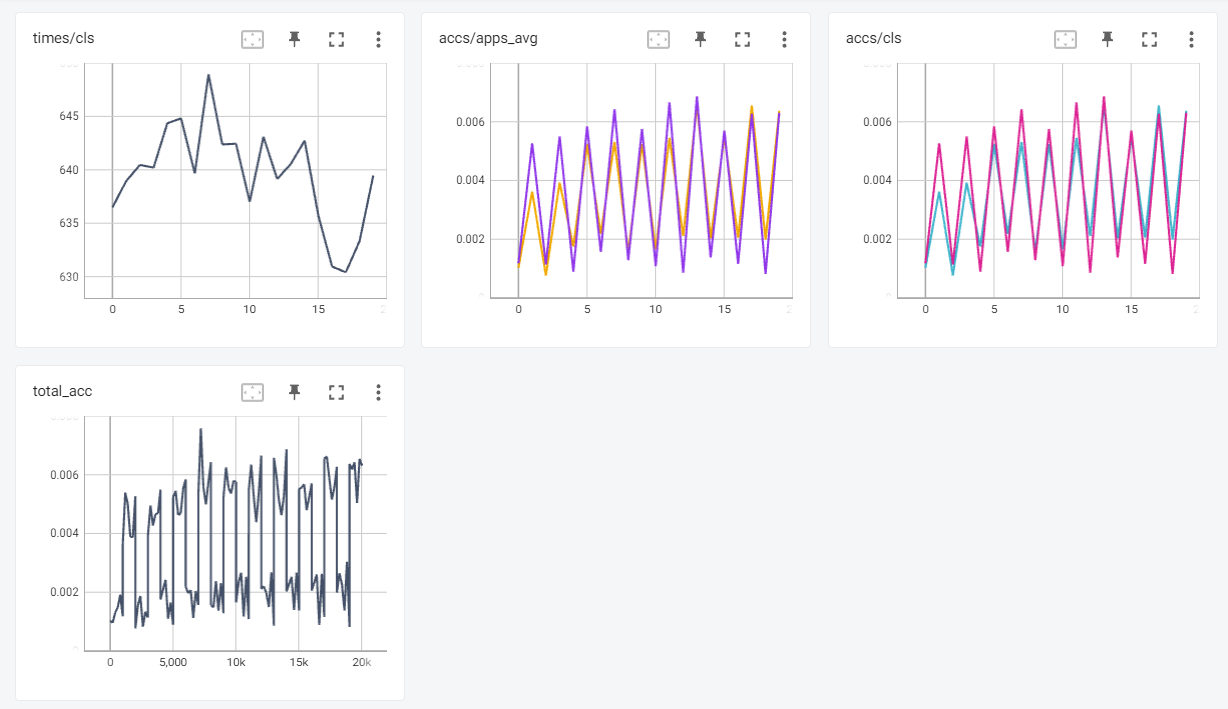
python new_impl/nlp/roberta/sentiment-classification/cls_online.py
You can launch TensorBoard to watch the retraining mAP50 score and time during the retraining process. Here is a screenshot:
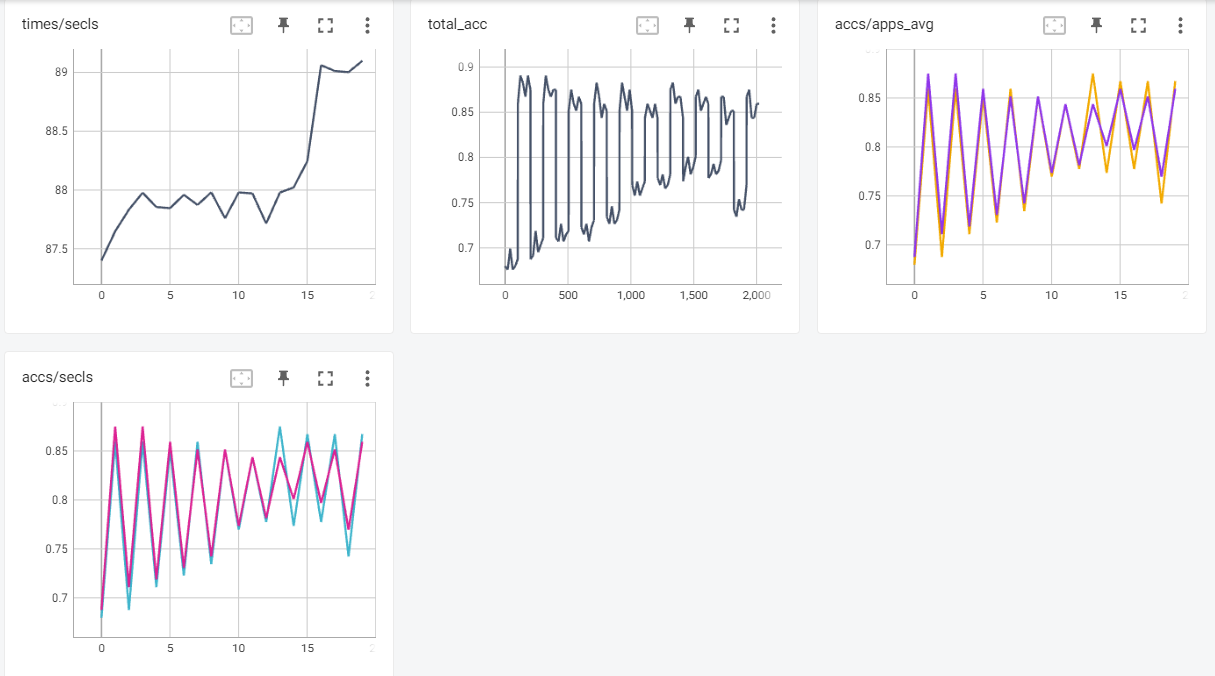 >
>
9. Implementation (Development API Documentation)
EdgeTA is implemented in Python with 8k LOCs and it is currently targeted for transformers running on commodity edge devices and Linux environment. Its scaling and retraining of transformers are implemented based on timm 0.9.1 and transformers 4.30.2. Its scheduler is built upon the optimization problem solver in scikit-opt 0.6.6 and resource management systems in Docker 10.03.6 and K3s 1.18.12.
Figure below illustrates the three steps of running a FM using EdgeTA. To facilitate the integration of a model, EdgeTA decouples the integration of a model (step 1) from its offline construction of knowledge base and neuron index (step 2) and online scaling and retraining of FM (step 3). This system design allows users only need to implement the FM API at step 1 to integrate a model. Specifically, EdgeTA supports two types of models.
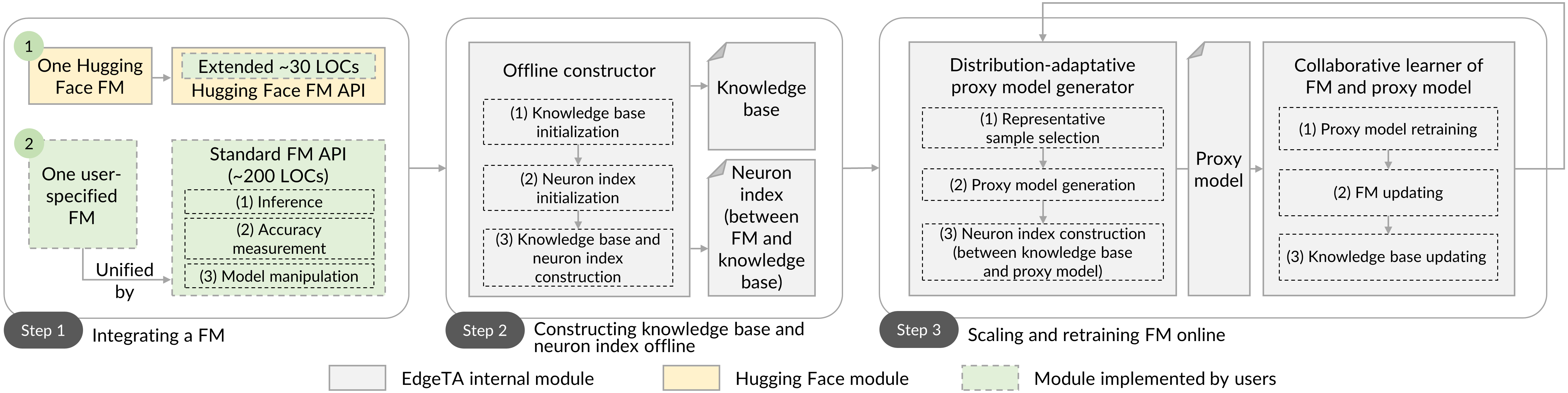
Hugging Face FMs. We implement EdgeTA to support FM APIs in the Hugging Face AI community. Using the AutoModel as example, EdgeTA calls function AutoModel.from_pretrained() to initialize a FM and calls function AutoModel.forward() to perform a forward operation. EdgeTA allows users to run a Hugging Face's FM using 30 about LOCs.
User-specified FMs. EdgeTA designs a standard FM API (colored by green in the figure) to unify user specified FM implementations. This API mainly defines: (i) how the FM performs an inference using the given sample; (ii) how the accuracy of the FM is measured using the given test dataset; (iii) how to manipulate (e.g. compress/update/remove) a specific layer in the FM. For each FM, this API can be implemented using about 200 LOCs.
9.1 Supporting a Hugging Face FM
Supporting a Hugging Face Model is a simplification of supporting a user-specified model, because Hugging Face FMs have many consistent implementation style so repetitive implementation work can be saved. The user can only implement the following several simple functions:
-
def get_feature_hook(self)- Get the PyTorch hook attached before the layer that extracts the key features.
- Output: A PyTorch hook.
-
def get_task_head_params(self)- Get the model parameters of the task head of the FM.
- Output: The model parameters of the task head of the FM.
-
def get_qkv_proj_ff1_ff2_layer_names(self)- Get a list of names, and each element in the list is a list that contains the names of Q/K/V layer, QKV projection layer, Feed Forward Layer 1, Feed Forward Layer 2. For example, for Hugging Face's BERT, this function should return [['bert.encoder.layer.0.attention.self.query', 'bert.encoder.layer.0.attention.self.key', 'bert.encoder.layer.0.attention.self.value', 'bert.encoder.layer.0.attention.output.dense', 'bert.encoder.layer.0.intermediate.dense', 'bert.encoder.layer.0.output.dense'], ['bert.encoder.layer.1.attention.self.query', 'bert.encoder.layer.1.attention.self.key', 'bert.encoder.layer.1.attention.self.value', 'bert.encoder.layer.1.attention.output.dense', 'bert.encoder.layer.1.intermediate.dense', 'bert.encoder.layer.1.output.dense'], ...]
- Output: A list of names.
-
def get_accuracy(self, test_loader)- Measure the accuracy of the FM using the given test data loader.
-
Inputs:
- test_loader: A given test dataloader.
- Output: The measured accuracy.
9.2 Supporting a user-specified FM
The user should implement the following functions in the standard FM API.
-
def forward(self, x, *args, **kwargs)- Let the FM perform a forward inference operation using the given sample x.
-
Inputs:
- x: A given sample.
- *args and **kwargs: Possible additional arguments used in the inference.
- Output: The inference results.
-
def get_accuracy(self, test_loader)- Measure the accuracy of the FM using the given test data loader.
-
Inputs:
- test_loader: A given test dataloader.
- Output: The measured accuracy.
-
def forward_to_get_task_loss(self, x, y *args, **kwargs)- Let the FM perform a forward operation using the given sample x, and calculate and return the task loss.
-
Inputs:
- x: A given sample.
- y: The corresponding label of x.
- *args and **kwargs: Possible additional arguments used in the inference.
- Output: The calculated task loss.
-
def get_feature_hook(self)- Get the PyTorch hook attached before the layer that extracts the key features.
- Output: A PyTorch hook.
-
def get_task_head_params(self)- Get the model parameters of the task head of the FM.
- Output: The model parameters of the task head of the FM.
-
def add_lora_ab_to_fm(self, ab_r: int, samples: torch.Tensor)- Add a LoRA matrix to each attention layer in the FM. The user should check if the FM's output is changed before and after the LoRA is added into the FM.
-
Inputs:
- ab_r: the factor r in LoRA.
- samples: A given sample for sanity check.
- Output: A PyTorch hook.
-
def fuse_lora_and_recover_net_structure(self, samples: torch.Tensor)- Fuse the added LoRA matrix into the corresponding attention layer in the FM, and recover the network structure to the original. This is invoked after the LoRA fine tuning.
-
Inputs:
- samples: A given sample for sanity check.
- Output: A PyTorch hook.
-
def is_q_or_k_v_linear(self, layer_name: nn.Module)- Check if the given layer is a Q/K/V Linear in the FM.
-
Inputs:
- layer_name: The name of a layer in the FM.
- Output: Return True if the given layer is a Q/K/V Linear in the FM.
-
def is_feed_forward(self, layer_name: nn.Module)- Check if the given layer is a feed forward layer in the FM.
-
Inputs:
- layer_name: The name of a layer in the FM.
- Output: Return True if the given layer is a feed forward layer in the FM.
-
def prune_an_attention_layer(self, attention_layer_name, sparsity: float, samples: torch.Tensor)- Pruning an attention layer.
-
Inputs:
- attention_layer_name: The name of target attention layer.
- sparsity: The pruning strength.
- samples: A given sample.
-
def prune_an_feed_forward_layer(self, feed_forward_layer_name, sparsity: float, samples: torch.Tensor)- Pruning an feed forward layer.
-
Inputs:
- feed_forward_layer_name: The name of target feed forward layer.
- sparsity: The pruning strength.
- samples: A given sample.
10. Experimental evaluation in ICDE 2024 submission
10.1 Basic settings
Testbeds. We evaluate EdgeTA on four heterogeneous edge devices: NVIDIA Jetson TX2 (8GB memory), NVIDIA Xavier NX (16GB memory), NVIDIA AGX Xavier (32GB memory), and NVIDIA AGX Orin (32GB memory).
Baselines. We compare EdgeTA with 13 adaptation methods, including 5 supervised continual learning methods and 8 unsupervised domain adaptation methods.
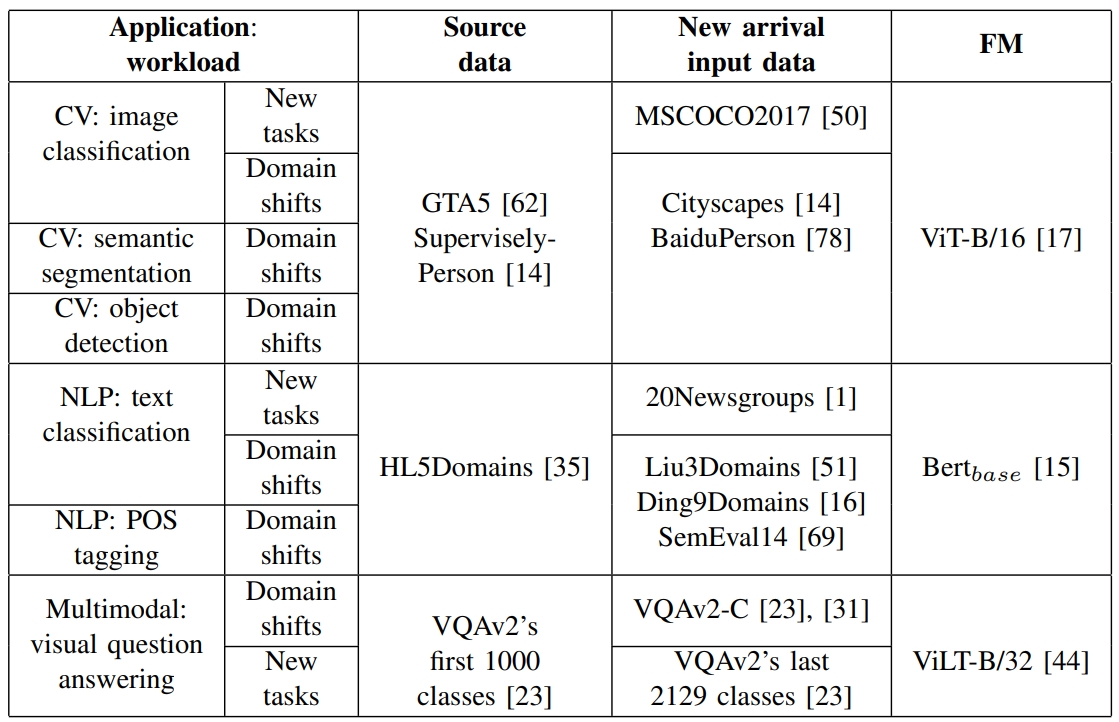
Workloads. We evaluate EdgeTA on three representative FMs: ViT-B/16 (CV), BERT_base (NLP), and ViLT (multimodal). ViT-B/16 is added three different application heads respectively to perform image classification, object detection, and semantic segmentation application. BERT_base is added two different application heads respectively to perform sentence classification and pos-of-tagging classification application. ViLT performs visual question answering application. Finally, GPT-Neo is evaluated in the discussion of PEFT techniques. We evaluate EdgeTA on 11 different datasets: GTA5, SuperviselyPerson, MSCOCO2017, Cityscapes, BaiduPerson, HL5Domains, Liu3Domains, Ding9Domains, SemEval14, 20Newsgroups, and VQAv2. More details refer to the table below.
10.2 Additional details
Online adaptation. For evolving domain shifts, EdgeTA uses the naive feature alignment (the most classical method for unsupervised domain adaptation) to retrain the proxy model. For evolving new tasks, EdgeTA uses the normal supervised learning to retrain the proxy model.
Applicability of baseline adaptation methods. Some baseline adaptation methods are inapplicable in some applications, so Figure 6, Table II, and Table III do not report their metrics. Specifically:
- SHOT and ConDA rely on pseudo labels, and their label generation algorithm can only generate the pseudo label with one dimension. However, the label in semantic segmentation application has three dimensions, the label in object detection application has bounding box information, the label in pos-of-tagging application has two dimensions, so SHOT and ConDA are inapplicable for these applications.
- BUFR calculates the KL divergence between the model's outputs in the source domain and the target domain, and the KL divergence only applies in the classification output. So BUFR is also inapplicable in semantic segmentation, object detection, and pos-of-tagging application.
- ACE uses a image generator so it is inapplicable in text classification, pos-of-tagging and visual question answering application.
10.3 Additional experiment results (applying EdgeTA in SOTA FMs: CLIP, SAM, GLIP, GPT-Neo and Roberta)
Besides the evaluated FMs in the submitted paper, there are some SOTA FMs. Some are SOTA CV FMs, such as CLIP for image classification, SAM for semantic segmentation, and GLIP for object detection, and the others are SOTA NLP FMs, such as GPT-Neo for text generation, and Roberta for sentiment classification. These SOTA FMs and the currently tested FMs have similar network architectures and sizes, that is, CLIP, SAM, and GLIP comprise a ViT and a GPT-2 (similar to BERT), as well as GPT Neo and Roberts including Transformer structure (the main structure used by BERT). We therefore expect EdgeTA still works well for these FMs.
To prove that, we ran a new set of experiments on CLIP, SAM, GLIP, GPT-Neo and Roberta to compare EdgeTA and CUA on NVIDIA Xavier NX. The results are demonstrated below. EdgeTA improves the accuracy by 12.71%, 7.36%, 6.41%, 10.81% and 10.38% for five FMs, respectively, which proves the applicability of EdgeTA to various FMs.
